در نرم افزار اکسل ابزاری برای آنالیز داده های آماری وجود دارد که مقادیری مثل میانگین، پراکندگی داده، انحراف معیار، محاسبه رگرسیون و ضریب همبستگی را به سادگی انجام میدهد. افزونهی Data Analysis Toolpak برای مقایسه و تحلیل داده های آماری مورد استفاده قرار می گیرد. این افزونه در حالت عادی فعال نیست و برای استفاده از آن لازم است که ابتدا آن را فعال نمود. در ادامه به فعالسازی این افزونه در نرم افزار اکسل می پردازیم.
برای این منظور ابتدا از سربرگ File به قسمت تنظیمات نرم افزار Excel می رویم. سپس به قسمت Add-ins رفته و از قسمت Manage گزینه Excel Add-ins را انتخاب کرده و کلید GO را فشار می دهیم.
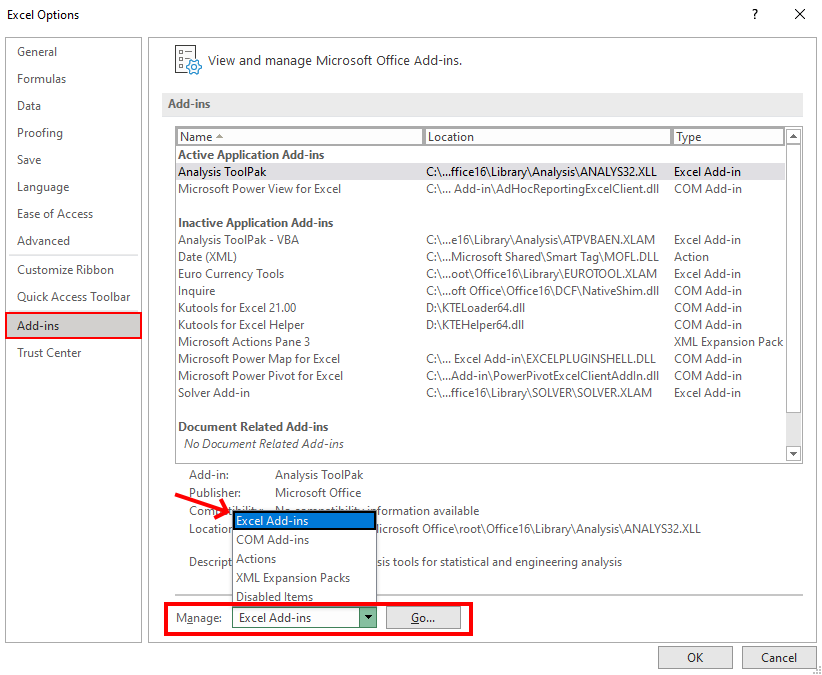
پس از انتخاب کلید GO پنجره دیگری به نمایش داده می شود و آنگاه تیک مربوط به گزینه Analysis Toolpak را فعال می کنیم و سپس روی OK کلیک می کنیم.

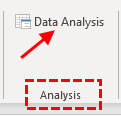
چنانچه مراحل را به درستی طی کرده باشیم، در سربرگ Data و در بخش Analysis، گزینه ای به نام Data Analysis نشان داده می شود.
اگر Data Analysis را انتخاب کنیم، متوجه می شویم که بسته ای حاوی ابزارهای مربوط به آنالیز و تحلیل وجو دارد که متناسب با نیازمان می توان از آن بهره ببریم.
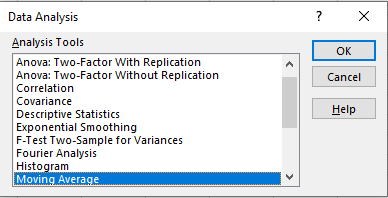
به توضیح فاکتورهای آماری در پنجره Data Analysis می پردازیم.
– گزینه Anova: Two-Factor With Replication برای تحلیل کردن واریانس در حالتی است که دو گروه از داده ها مستقل هستند.
– گزینه Anova: Two-Factor Without Replication برای تحلیل کردن واریانس در حالتی است که دو متغیر مستقل داریم و در اندازهگیری، داده های کپی وجود ندارد.
– Correlation یا ضریب همبستگی ارتباط بین داده ها را تحلیل می کند. ضریب همبستگی همواره عددی بین (۱ و ۱-) است. هرچه مقدار مطلق ضریب همبستگی (صرفنظر از علامت) به عدد ۱ نزدیک باشد، نشان میدهد شدت رابطه خطی بین دو متغیر قویتر است.
– گزینه بعدی Covariance یا کوواریانس است که روشی آماري است که اجازه می دهد اثر یک متغیر مستقل بر متغیر وابسته مورد بررسی قرار گیرد در حالی که اثر متغیر دیگري را حذف کرده و یا از بین می برد. تحلیل کواریانس به ما کمک می کند تا از شر اثرات مربوط به متغیر مداخله گر خلاص شویم، اثر این کار کم کردن میزان خطاي واریانس است. از تحلیل کواریانس معمولا در طرح هاي پیش آزمون – پس آزمون استفاده می شود. در این طرح ها قبل از اینکه آزمودنی ها در شرایط آزمایشی قرار گیرند، یک آزمون بر روي آنها انجام می شود و سپس بعد از قرار گرفتن در شرایط آزمایشی همان آزمون بر روي آنها انجام می شود.
– گزینهی Descriptive Statistics به معنای آمار توصیفی است. آمار توصیفی ویژگی های یک مجموعه داده را خلاصه یا توصیف می کند. آمار توصیفی از دو دسته اصلی معیارها تشکیل شده است: معیارهای گرایش مرکزی و معیارهای تغییرپذیری (یا پراکندگی). ویژگی هایی مانند میانگین، میانه، ضریب چولگی، ضریب کشیدگی و … در یک جدول گزارش می دهد.
– یکسان سازی نمایی یا Exponential Smoothing یک روش کلی برای هموارسازی داده های سری زمانی با استفاده از تابع پنجره نمایی است. در حالی که در میانگین متحرک ساده، مشاهدات گذشته به طور مساوی وزن داده می شوند، از توابع نمایی برای تخصیص وزن های کاهش نمایی در طول زمان استفاده می شود. این روشی است که به راحتی آموخته می شود و به راحتی برای تعیین برخی از فرضیات قبلی توسط کاربر، مانند فصلی بودن، اعمال می شود. هموارسازی نمایی اغلب برای تجزیه و تحلیل داده های سری زمانی استفاده می شود.
– از ابزار F-Test Two-Sample for Variances برای آزمایش اینکه آیا واریانس دو جمعیت برابر است، استفاده می شود. این تست می تواند یک تست دو طرفه یا یک تست یک طرفه باشد. هرچه این نسبت به دست آمده از عدد 1 بیشتر باشد، نشان می دهد که واریانس جمعیت نابرابر، قوی تر است.
– گزینه Fourier Analysis برای تجزیه و تحلیل داده ها بسیار مفید است، زیرا سیگنال را به نمودارهای سینوسی تشکیل دهنده با فرکانس های مختلف تجزیه می کند. این ابزار به ویژه در زمینه هایی مانند پردازش سیگنال و تصویر پردازش آنها مفید است، جایی که کاربردهای آن از فیلتر کردن، پیچیده شدن و تجزیه و تحلیل فرکانس تا تخمین طیف قدرت را شامل می شود.
– نمودار Histogram نموداری است که داده ها را به نمودارهای مستطیلی شکل برای فهم آسان تر و توصیف بهتر مطالب تبدیل می کند. کاربرد این نمودارها بسیار زیاد است، به عنوان مثال از نمودار هیستوگرام در بسیاری از داشبوردهای مدیریتی که امروزه در دنیا وجود دارد، استفاده میکنند.
– Moving Average یه روش به معنی میانگین متحرک است که می توان داده هایی که ترتیب زمانی دارند را تحلیل و بررسی کرد. کاربرد این روش در مبحث سری های زمانی است.
– ابزار Random Number Generation ابزار تولید داده های تصادفی است. داده های تصادفی در فرایند شبیه سازی، نمونه برداری آماری، رمزنگاری و سایر زمینههایی که تولید یک نتیجه غیرقابل پیشبینی مطلوب است، کاربرد دارد.
– از گزینه Rank and Percentile می توان به سرعت برای یافتن رتبه همه مقادیر و صدک آنها در یک لیست استفاده کرد. مزیت استفاده از ویژگی Rank و Percentile این است که صدک نیز به جدول خروجی اضافه می شود. صدک درصدی است که نشان دهنده نسبت لیست است که زیر یک عدد معین است.
– Regression یا همان رگرسیون از تحلیل های مهم و پرکاربرد در علم آمار است و مشخص می کند که چه عواملی اثر زیادی روی پدیده ها دارند و میزان ارتباط بین آنها را مشخص می کند.
– گزینه Sampling یا نمونه برداری که بخشی از دستور تجزیه و تحلیل داده ها در اکسل است، می توان به طور تصادفی آیتم ها را از یک مجموعه داده انتخاب کرد. فرض کنیم می خواهیم به طور تصادفی پنج عنوان را از فهرستی از کتاب انتخاب کنیم، برای این کار می توانیم از ابزار Sampling استفاده کنیم.
– ابزار t-Test: Paired Two Sample for Means برای هنگامی است که دو مجموعه داده که مربوط به یک جامعهی آماری در دو زمان مختلف است را مقایسه کنیم.
– ابزار t-Test: Two-Sample Assuming Equal Variances برای زمانی است که بخواهیم دو گروه داده مربوط به اندازه گیری در دو جامعهی آماری متفاوت و مستقل را مقایسه کنیم.
– ابزار t-Test: Two-Sample Assuming Unequal Variances برای مواقعی است که دو گروه داده مربوط به دو جامعهی آماری داریم به طوری که واریانس نیز مساوی نیست.
– ابزار z-Test: Two Sample for Means برای مقایسه میانگین دو نمونه استفاده می شود تا ببینیم آیا امکان پذیر است که آنها از یک جامعه آمده باشند یا خیر. فرض صفر این است که میانگین جمعیت برابر است.